Generating Slovenian Names with Keras/TensorFlow
Generative Deep Learning
Recurrent neural networks can be used to generate sequence data such as text. The usual way to generate sequence data in deep learning is to train a network that predicts the next token in a sequence using the previous tokens as input. Let’s explore how this method can be used to generate new Slovenian–sounding names. The same approach could be used for generating original company, brand or product names.
This project was inspired by this talk by Jacqueline Nolis and the code was mostly “stolen” from this GitHub repo.
Data Preparation
A list of 667 Slovenian names has been obtained from this website.
library(tidyverse)
library(janitor)
library(keras)
# data import -------------------------------------------------------------
# source: http://www.mojmalcek.si/clanki_in_nasveti/nosecnost/118/650_imen_za_novorojencka.html
names <- read_csv('data/names.txt') %>% clean_names()
# data cleaning -----------------------------------------------------------
names <- names %>% filter(str_length(name) > 1)
names
## # A tibble: 667 x 1
## name
## <chr>
## 1 ADA
## 2 ADAM
## 3 ADELA
## 4 ADELAJDA
## 5 ADRIJAN
## 6 ADRIJANA
## 7 AGATA
## 8 AJA
## 9 AJDA
## 10 AJETA
## # ... with 657 more rows
Note that this is a list of distinct names and not a sample of names from population as in the original project. Also, the size of the training data is much smaller here.
From each name we are going to create a bunch of training examples. The goal of the model that we are going to build is to predict the next letter from the previous ones.
# modify the data so it's ready for a model
# first we add a character to signify the end of the name ("+")
# then we need to expand each name into subsequences (S, SP, SPO, SPOT) so we can predict each next character.
# finally we make them sequences of the same length. So they can form a matrix
# the subsequence data
subsequence_data <-
names %>%
mutate(accumulated_name =
name %>%
str_c("+") %>% # add a stop character
str_split("") %>% # split into characters
map(~purrr::accumulate(.x, c)) # make into cumulative sequences
) %>%
select(accumulated_name) %>% # get only the column with the names
unnest(accumulated_name) %>% # break the cumulations into individual rows
arrange(runif(n())) %>% # shuffle for good measure
pull(accumulated_name) # change to a list
Next, we create the character_lookup table where each letter is assigned to a number.
character_lookup <- data.frame(character = c(LETTERS, "Č", "Š", "Ž", ".", "-", " ", "+"),
stringsAsFactors = FALSE)
character_lookup[["character_id"]] <- 1:nrow(character_lookup)
max_length <- 10
num_characters <- nrow(character_lookup) + 1
Next step is to create a 3-dimensional text_matrix where each training example is represented by 11 characters. We want to predict the 11th character from the 10 previous ones. Padding with zeros is applied to cases with less than 10 predictor characters. All characters are 1–hot encoded into 34 “slots” of the third dimension.
# the name data as a matrix. This will then have the last character split off to be the y data
# this is nowhere near the fastest code that does what we need to, but it's easy to read so who cares?
text_matrix <-
subsequence_data %>%
map(~character_lookup$character_id[match(.x, character_lookup$character)]) %>% # change characters into the right numbers
pad_sequences(maxlen = max_length + 1) %>% # add padding so all of the sequences have the same length
to_categorical(num_classes = num_characters) # 1-hot encode them (so like make 2 into [0,1,0,...,0])
dim(text_matrix)
## [1] 4455 11 34
We can now extract the x and y matrices that will be used in model training.
x_name <- text_matrix[, 1:max_length, ] # make the X data of the letters before
y_name <- text_matrix[, max_length + 1, ] # make the Y data of the next letter
Creating the Model
We will use a two-layer LSTM network. Because we are performing multiclass, single–label classification, softmax activation and categorical crossentropy loss function must be used.
# the input to the network
input <- layer_input(shape = c(max_length, num_characters))
# the name data needs to be processed using an LSTM,
# Check out Deep Learning with R (Chollet & Allaire, 2018) to learn more.
output <-
input %>%
layer_lstm(units = 64, return_sequences = TRUE) %>%
layer_lstm(units = 64, return_sequences = FALSE) %>%
layer_dropout(rate = 0.1) %>%
layer_dense(num_characters) %>%
layer_activation("softmax")
# the actual model, compiled
model <- keras_model(inputs = input, outputs = output) %>%
compile(
optimizer = "adam",
loss = 'categorical_crossentropy',
metrics = c("accuracy")
)
We are now ready to fit the model.
# here we run the model through the data 100 times.
fit_results <- model %>% keras::fit(
x_name,
y_name,
batch_size = 64,
epochs = 100,
validation_split = 0.1
)
plot(fit_results)
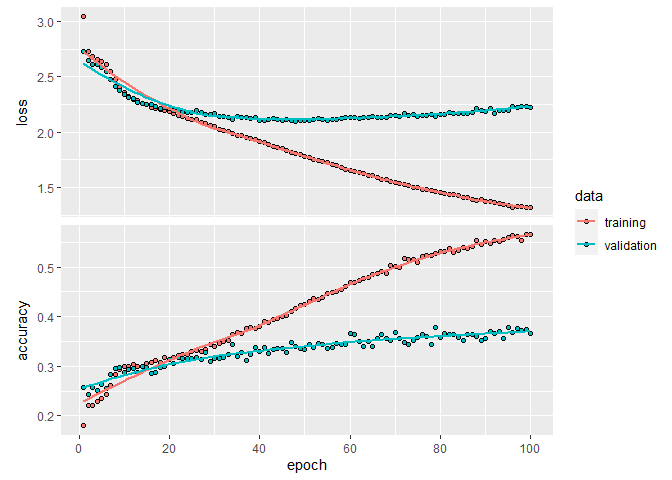
The achieved validation accuracy and loss are not that great here. One reason for this is the fact that we are working with a list of distinct names. The alternative, a sample of names from population, would yield better results because some names from the validation set would have been present in the training set.
# save the model so that it can be used in the future
save_model_hdf5(model,"models/model.h5")
Generating the Names
We are now going to use this model for generation of new names.
The concept of temperature is introduced here. It controls how surprising or predictable the choice of the next character will be. Higher temperatures will produce more surprising results, whereas lower temperature will result in less randomness and more predictable outcomes.
Let’s define some functions that will be used in this final step.
# a function that generates a single name from a model
generate_name <- function(model, character_lookup, max_length, temperature = 1){
# model - the trained neural network
# character_lookup - the table for how characters convert to numbers
# max_length - the expected length of the training data in characters
# temperature - how weird to make the names, higher is weirder
choose_next_char <- function(preds, character_lookup, temperature = 1){
preds <- log(preds) / temperature
exp_preds <- exp(preds)
preds <- exp_preds / sum(exp(preds))
next_index <- which.max(as.integer(rmultinom(1, 1, preds)))
character_lookup$character[next_index - 1]
}
in_progress_name <- character(0)
next_letter <- ""
# while we haven't hit a stop character and the name isn't too long
while(next_letter != "+" && length(in_progress_name) < 30){
# prep the data to run in the model again
previous_letters_data <-
lapply(list(in_progress_name), function(.x){
character_lookup$character_id[match(.x, character_lookup$character)]
})
previous_letters_data <- pad_sequences(previous_letters_data, maxlen = max_length)
previous_letters_data <- to_categorical(previous_letters_data, num_classes = num_characters)
# get the probabilities of each possible next character by running the model
next_letter_probabilities <-
predict(model,previous_letters_data)
# determine what the actual letter is
next_letter <- choose_next_char(next_letter_probabilities,character_lookup,temperature)
if(next_letter != "+")
# if the next character isn't stop add the latest generated character to the name and continue
in_progress_name <- c(in_progress_name,next_letter)
}
# turn the list of characters into a single string
raw_name <- paste0(in_progress_name, collapse = "")
# capitalize the first letter of each word
capitalized_name <- str_to_title(raw_name)
return(capitalized_name)
}
# a function to generate many names
generate_many_names <- function(n = 10, model, character_lookup, max_length, temperature = 1){
# n - the number of names to generate
# (then everything else you'd pass to generate_name)
return(unlist(lapply(1:n, function(x) generate_name(model, character_lookup, max_length, temperature))))
}
# a function to generate many new names: names from the training set are removed from result
generate_many_new_names <- function(n = 10, model, character_lookup, max_length, temperature = 1, names){
# names - training dataset with original names
# n - number of names the model generates, NOT all of them are new so the output is usually smaller
return(
generate_many_names(n, model, character_lookup, max_length, temperature) %>%
enframe() %>%
select(name = value) %>%
distinct() %>%
anti_join(names %>% mutate(name = str_to_title(name)), by = 'name') %>%
arrange(name) %>%
pull()
)
}
Results
Temperature = 0.2
generate_many_new_names(n = 200, model, character_lookup, max_length, temperature = 0.2, names)
## [1] "Ala" "Alonzija" "Amada" "Darija" "Doro" "Doronc"
## [7] "Orika" "Orist" "Sanko" "Sarka" "Timorij" "Vitomijan"
Temperature = 0.4
generate_many_new_names(n = 200, model, character_lookup, max_length, temperature = 0.4, names)
## [1] "Alina" "Alonja" "Alonsa" "Amad" "Amada"
## [6] "Aman" "Anaela" "Anal" "Arma" "Borita"
## [11] "Darisa" "Demilij" "Domin" "Dorica" "Doro"
## [16] "Doronc" "Ezdan" "Herget" "Ila" "Iven"
## [21] "Jane" "Janmin" "Kotmen" "Lajza" "Lida"
## [26] "Lodija" "Lovri" "Ložva" "Mara" "Marica"
## [31] "Marka" "Marto" "Milana" "Mita" "Mojana"
## [36] "Nadeland" "Orencina" "Orist" "Ornesdija" "Porolca"
## [41] "Rama" "Rezani" "Selija" "Sivo" "Vaj"
## [46] "Zevga" "Zvatimija" "Zvenko" "Zvonislava"
Temperature = 0.6
generate_many_new_names(n = 200, model, character_lookup, max_length, temperature = 0.6, names)
## [1] "Adra" "Alaš" "Alina" "Amada" "Anaeta"
## [6] "Anur" "Arma" "Bia" "Bitjaž" "Blak"
## [11] "Calre" "Ciles" "Dabijana" "Daja" "Daman"
## [16] "Damana" "Davija" "Denik" "Dorinc" "Doronc"
## [21] "Dožina" "Elizava" "Gara" "Goman" "Groga"
## [26] "Hadrija" "Hebrirt" "Iman" "Isa" "Jamor"
## [31] "Jane" "Kromir" "Lavrina" "Leda" "Lodija"
## [36] "Magdar" "Marica" "Marka" "Martij" "Merisa"
## [41] "Miba" "Miga" "Mito" "Mojana" "Nejca"
## [46] "Oggjan" "Ojna" "Olevert" "Orgen" "Orget"
## [51] "Oriha" "Orist" "Ornestija" "Orneta" "Pando"
## [56] "Porleca" "Rama" "Rodi" "Ruzal" "Sanko"
## [61] "Savela" "Sivo" "Sverta" "Tada" "Tana"
## [66] "Terizeja" "Timen" "Timena" "Timorij" "Toman"
## [71] "Tonča" "Tončekla" "Tonika" "Tozeza" "Vance"
## [76] "Vanesta" "Varter" "Vasela" "Vatjaž" "Verta"
## [81] "Vistjan" "Zvonislava" "Žaš" "Žebert" "Želistav"
## [86] "Žrenka"
Temperature = 0.8
generate_many_new_names(n = 200, model, character_lookup, max_length, temperature = 0.8, names)
## [1] "Adeja" "Adla" "Adra" "Adroja" "Akda"
## [6] "Alša" "Amada" "Anaeta" "Anmen" "Arna"
## [11] "Arona" "Avdra" "Avronija" "Benemin" "Benjan"
## [16] "Binca" "Bogej" "Boja" "Bolitar" "Bora"
## [21] "Borta" "Bortel" "Bošcja" "Božida" "Bragica"
## [26] "Bramir" "Brank" "Cirela" "Curta" "Damer"
## [31] "Dana" "Dava" "Debija" "Dobanca" "Dolil"
## [36] "Dono" "Etizka" "Ezna" "Fendi" "Franco"
## [41] "Gika" "Givo" "Gorand" "Hariela" "Herget"
## [46] "Imen" "Irona" "Izan" "Jerij" "Jubel"
## [51] "Kamar" "Karja" "Kiara" "Kjastin" "Klavdika"
## [56] "Klavdina" "Larmo" "Lavda" "Lelida" "Lenasta"
## [61] "Lodija" "Lovrin" "Ložika" "Ludorf" "Magdara"
## [66] "Magelija" "Maksimir" "Martis" "Marto" "Matet"
## [71] "Mehani" "Mena" "Milana" "Milijana" "Miljan"
## [76] "Morika" "Morit" "Nad" "Nadravja" "Nedelja"
## [81] "Neotja" "Neta" "Nidor" "Orika" "Orist"
## [86] "Oruka" "Oter" "Pavrif" "Pavrla" "Poli"
## [91] "Ranue" "Rastija" "Reda" "Redilan" "Relestan"
## [96] "Reska" "Ronko" "Sanka" "Saver" "Sefdinen"
## [101] "Siba" "Sibor" "Sila" "Sizena" "Tada"
## [106] "Tebeja" "Tomož" "Toniela" "Tonika" "Tonja"
## [111] "Vaj" "Vajter" "Valestija" "Vara" "Vejda"
## [116] "Virij" "Vitej" "Vojtem" "Zalja" "Zana"
## [121] "Zarbija" "Zlaša" "Zola" "Zonja" "Zvido"
## [126] "Zvonislava"
Temperature = 1
generate_many_new_names(n = 200, model, character_lookup, max_length, temperature = 1, names)
## [1] "Aence" "Afžimer" "Aharo" "Ajto" "Alaksavd"
## [6] "Alaša" "Aljanz" "Amako" "Amanja" "Amind"
## [11] "Anasta" "Anbelija" "Anbrijel" "Ariza" "Begranika"
## [16] "Biana" "Bonica" "Borika" "Borta" "Cajrt"
## [21] "Cbrastija" "Cllala" "Cvenka" "Daro" "Daška"
## [26] "Davi" "Doni" "Doolje" "Dula" "Dužan"
## [31] "Elnaž" "Ernado" "Etenia" "Evit" "Fendi"
## [36] "Fiks" "Flanci" "Flanko" "Franiša" "Fransi"
## [41] "Fronja" "Frorj" "Gibir" "Gjana" "Glada"
## [46] "Goniela" "Gonjen" "Guro" "Ifran" "Ila"
## [51] "Imon" "Jelcka" "Juba" "Jubija" "Judor"
## [56] "Kajčenn" "Kanmen" "Karet" "Karimijana" "Klever"
## [61] "Konstanc" "Konstarda" "Ksavila" "Ksejna" "Lalisa"
## [66] "Lava" "Lavica" "Leza" "Ljubimir" "Ludolika"
## [71] "Mabela" "Madra" "Madulija" "Magoja" "Maksmrjan"
## [76] "Mansika" "Mariel" "Marila" "Marka" "Marnisa"
## [81] "Matel" "Mehnini" "Mira" "Morina" "Nana"
## [86] "Nead" "Nejco" "Nete" "Nežpa" "Nukoja"
## [91] "Nvak" "Obga" "Oman" "Omanda" "Onja"
## [96] "Onjencink" "Ornek" "Pavlelca" "Peha" "Pela"
## [101] "Potoj" "Redeja" "Roborta" "Roma" "Ruko"
## [106] "Samin" "Sanko" "Seborij" "Seoštija" "Sigo"
## [111] "Sjana" "Somen" "Stan" "Subila" "Šzmao"
## [116] "Tibera" "Tileja" "Tjaža" "Toma" "Tožka"
## [121] "Ulorija" "Urena" "Vadra" "Vajda" "Valca"
## [126] "Vastija" "Veria" "Vetčda" "Vica" "Vitofija"
## [131] "Zglaga" "Zina" "Zmak" "Zona" "Zšhenka"
## [136] "Zveto" "Zvito" "Zvoziz" "Žamo" "Žav"
## [141] "Želistij" "Žiša" "Žorko"
As expected, with lower temperatures the model generated more existing names from the training data as with higher temperatures. Also, some actual Slovenian names that were not present in the incomplete input table have been generated.
GitHub
https://github.com/tomazweiss/slovenian-name-generator
Found this content interesting or useful? Fuel future articles with a coffee!

Session Info
sessionInfo()
## R version 4.0.2 (2020-06-22)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 10 x64 (build 18363)
##
## Matrix products: default
##
## locale:
## [1] LC_COLLATE=Slovenian_Slovenia.1250 LC_CTYPE=Slovenian_Slovenia.1250
## [3] LC_MONETARY=Slovenian_Slovenia.1250 LC_NUMERIC=C
## [5] LC_TIME=Slovenian_Slovenia.1250
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] keras_2.3.0.0 janitor_2.0.1 forcats_0.5.0 stringr_1.4.0
## [5] dplyr_1.0.2 purrr_0.3.4 readr_1.4.0 tidyr_1.1.2
## [9] tibble_3.0.4 ggplot2_3.3.2 tidyverse_1.3.0
##
## loaded via a namespace (and not attached):
## [1] Rcpp_1.0.5 lubridate_1.7.9.2 lattice_0.20-41 assertthat_0.2.1
## [5] zeallot_0.1.0 digest_0.6.27 utf8_1.1.4 R6_2.5.0
## [9] cellranger_1.1.0 backports_1.2.0 reprex_0.3.0 evaluate_0.14
## [13] httr_1.4.2 pillar_1.4.7 tfruns_1.4 rlang_0.4.9
## [17] readxl_1.3.1 rstudioapi_0.13 whisker_0.4 Matrix_1.2-18
## [21] reticulate_1.18 rmarkdown_2.6 labeling_0.4.2 splines_4.0.2
## [25] munsell_0.5.0 broom_0.7.3 compiler_4.0.2 modelr_0.1.8
## [29] xfun_0.19 pkgconfig_2.0.3 base64enc_0.1-3 mgcv_1.8-31
## [33] tensorflow_2.2.0 htmltools_0.5.0 tidyselect_1.1.0 fansi_0.4.1
## [37] crayon_1.3.4 dbplyr_2.0.0 withr_2.3.0 rappdirs_0.3.1
## [41] grid_4.0.2 nlme_3.1-148 jsonlite_1.7.2 gtable_0.3.0
## [45] lifecycle_0.2.0 DBI_1.1.0 magrittr_2.0.1 scales_1.1.1
## [49] cli_2.2.0 stringi_1.5.3 farver_2.0.3 fs_1.5.0
## [53] snakecase_0.11.0 xml2_1.3.2 ellipsis_0.3.1 generics_0.1.0
## [57] vctrs_0.3.6 tools_4.0.2 glue_1.4.2 hms_0.5.3
## [61] yaml_2.2.1 colorspace_2.0-0 rvest_0.3.6 knitr_1.30
## [65] haven_2.3.1